谷歌優化升級網絡架構,打造生成式 AI 推理與訓練高效利器

谷歌一位網絡領域專家晉升至核心管理層、執掌這家搜索引擎、廣告巨頭(如今更是 AI 巨頭)的基礎設施研發業務,這絕非偶然。尤其關鍵的是,谷歌幾乎已經落地了解耦式數據中心基礎設施架構 —— 過去十余年間,我們一直在持續探討、追蹤這一技術方向。
在解耦、可組合的數據中心架構體系中,網絡始終處于核心樞紐位置。企業不僅需要對網絡進行性能調優,更要針對性定制專用網絡,使其高度適配特定業務負載,這也是差異化網絡架構誕生的核心原因。
傳統一體化服務器被拆解為獨立硬件單元,以機架模塊化方式部署,算力、內存、I/O、加速卡、存儲資源可自由組合,靈活構建不同規格的虛擬集群:小集群承載輕量化分布式任務,超大規模集群專注單一巨型 AI 作業。這套復雜架構,絕非僅靠在機架內堆疊 PCIe 交換芯片就能實現。
從傳統分布式計算、存儲系統,到跨區域、全球化數據中心互聯,專用網絡與通信協議正迎來全面普及。谷歌自研網絡技術布局已久:2019 年,谷歌公開基于 Linux 自研的網絡操作系統Snap,以及配套數據面引擎 Pony Express,該套方案早在 2016 年便已投入量產部署。
四年前,谷歌推出Aquila協議,可為小規模緊耦合集群提供媲美 InfiniBand 的超低時延能力;同步配套研發機架頂置網卡芯片 TiN,基于蜻蜓全互聯拓撲,實現千節點集群的定制化組網。此外,谷歌與英特爾聯合為 “芒特埃文斯” DPU 打造Falcon低時延網絡傳輸接口,進一步豐富低延遲算力互聯方案。
上周谷歌正式發布TPU 8系列芯片,面向推理場景的 TPU 8i 與面向訓練場景的 TPU 8t 同步亮相。本文將深度解析兩大核心技術:一是谷歌自研的Boardfly 芯片間互聯(ICI) 全新拓撲,用于 TPU 算力集群組網,并實現跨芯片一定程度的內存一致性;二是全新室女座(Virgo) 橫向擴展級以太網架構,面向全域數據中心規模部署,全面適配 TPU 集群及各類服務器機架互聯。
此前歷代 TPU 集群均采用環形拓撲組網:中小規模集群使用二維環網,搭載數千顆 TPU 的超大規模計算集群則升級為三維環網。
環形拓撲具備多維度互聯特性,廣泛應用于超級計算機架構:IBM 藍色基因大型并行超算、富士通研發的 “K 超算” 與 “富岳超算” 搭載的六維 Tofu 互聯架構,均是典型案例。
環形拓撲適合海量硬件節點組網,但橫向擴容難度極高。二維環網最大僅支持 256 顆加速卡互聯;谷歌上一代鐵木 TPU v7e 采用的三維環網,上限為 9216 顆加速卡;而全新太陽魚 TPU 8t 訓練集群,依托升級版三維環網,將單系統鏡像互聯規模提升至 9600 顆 TPU。
環形拓撲適配分布式并行計算,但設備間數據轉發跳數過多,會顯著增加傳輸時延,該特性勉強滿足大模型訓練需求,卻完全無法適配推理業務。推理場景的核心目標是極致降本,且存在大量全規約、全互聯通信需求,當前主流混合專家(MoE)大模型尤為依賴高頻低延遲互聯。
為此,谷歌為斑馬魚 TPU 8i 推理芯片量身打造Boardfly 全新拓撲架構。該架構單集群可實現 1152 顆 TPU 8i 一體化內存與算力協同組網;同等規模下,網絡轉發跳數從三維環網的 16 跳壓縮至 7 跳。
Boardfly 拓撲借鑒近十五年超算領域普及的蜻蜓拓撲設計,推理集群網絡直徑降低 56%,大幅削減數據傳輸尾延遲。谷歌實測數據顯示,在推理負載下,Boardfly 架構的數據傳輸平均時延,較三維環網直接降低 50%。
時延優化能夠充分釋放 TPU 8i 內置的集合通信加速引擎(CAE) 卸載芯片性能,保障硬件算力持續滿載輸出。更強的原生算力、扁平化Boardfly 互聯架構與專用 CAE 加速單元形成協同,讓全新推理集群的整體吞吐性能,較上一代鐵木平臺實現三倍及以上躍升。
下面是另一個

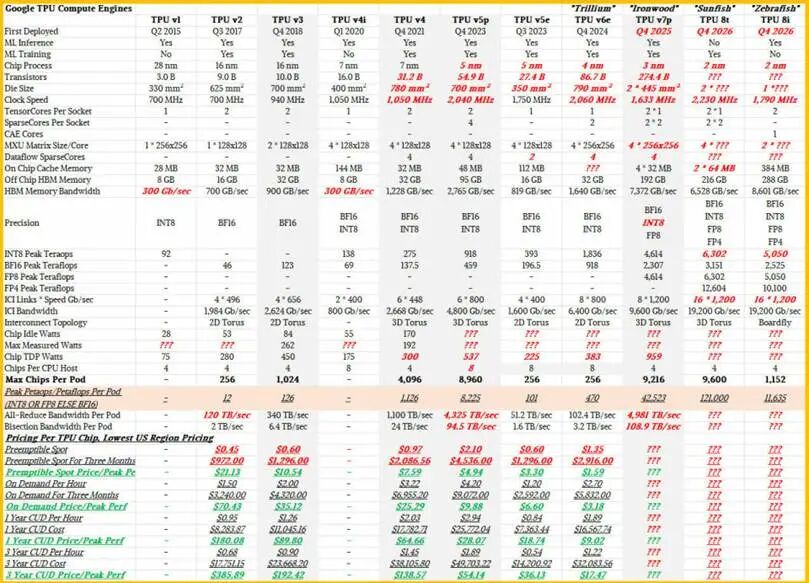
在 Boardfly 架構中,單塊斑馬魚系統板搭載 8 顆 TPU 8i,通過芯片間互聯端口實現板內全互聯;每顆芯片預留冗余互聯端口,可將 8 塊系統板進一步級聯,構建機架級 32 顆 TPU 全互聯體系,機架內任意兩顆芯片僅需 1~2 跳即可完成通信,且全程采用低成本銅纜互聯。
如需擴展至 1152 顆 TPU、合計 36 組算力單元的超大規模推理集群,谷歌接入阿波羅(Apollo) 光電路交換設備(隸屬木星數據中心骨干網絡),實現跨集群高速互聯。
這套「芯片間互聯 + 光電路交換」組合架構,是跳數大幅壓縮的關鍵:光交換設備搭載海量光口,推理系統板可集成更多光收發模塊,大幅提升板間光纖互聯密度。對比上一代三維環網,32 節點集群的光電互聯鏈路數量提升約 4~8 倍,硬件互聯瓶頸徹底解除。

面向 AI 訓練的規模化組網升級
AI 訓練與推理的負載需求截然不同,谷歌會盡可能減少光電路交換設備的使用 —— 相較于博通、思科、英偉達 ASIC 架構的以太網交換機,光交換硬件成本更高、供給更稀缺。
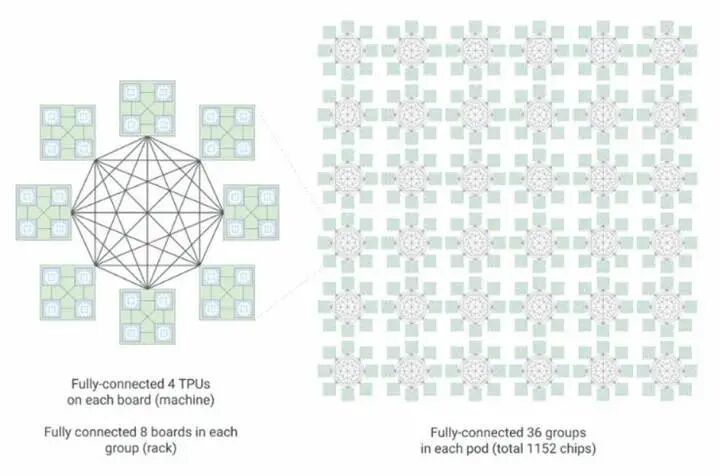
谷歌并未完整披露室女座(Virgo)橫向擴展網絡的底層硬件參數,但明確了核心設計思路:不再單純追求單端口超高速率,而是平衡帶寬需求、高基數端口密度與扁平化網絡架構,通過減少轉發跳數控制整體部署成本。
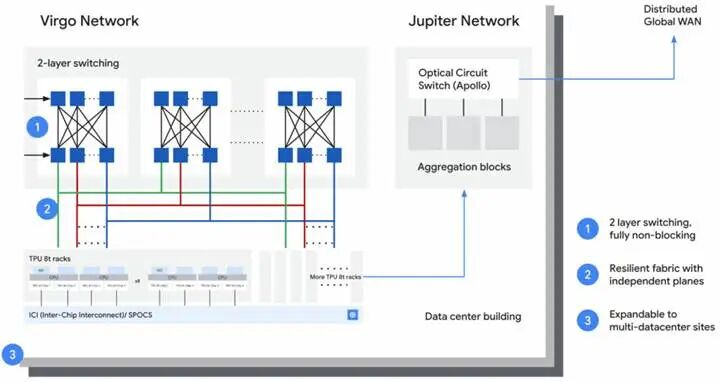
技術層面,Virgo 架構為 GPU、TPU 等加速卡機架,構建扁平化、無阻塞雙層全域互聯拓撲。阿波羅光交換設備不再用于訓練集群橫向擴容,僅負責對接谷歌數據中心內通用算力、存儲資源池。
官方數據顯示,單套 Virgo 網絡架構可無縫互聯多達 13.4 萬顆 TPU 8t 芯片,提供 47PB/s 無阻塞二分帶寬;太陽魚 TPU 8t 單芯片橫向擴展帶寬達 400Gb/s,是上一代鐵木 v7e 100Gb/s 端口帶寬的四倍,網絡架構時延同步降低 40%。
谷歌超大規格 TPU 訓練集群的構建邏輯清晰:單集群內,依托三維環網芯片間互聯,最高可容納 9600 顆 TPU 8t 算力芯片;結合深度優化 RDMA 協議、借鑒 Aquila 協議與 TiN 混合交換網卡技術的 Virgo 數據中心網絡,再疊加 JAX、Pathways 兩大 AI 框架專屬優化,單套 Virgo 組網可支撐 13.4 萬顆TPU 協同訓練。
多套 Virgo 架構通過光電路交換設備級聯后,可組建百萬級 TPU超大型邏輯訓練集群,滿足萬億參數大模型、通用人工智能的極限訓練需求。
除此之外,谷歌為 TPU 8t 新增原生 RDMA 支持,推出兩大關鍵技術:TPU 直連 RDMA與TPU 直連存儲。兩項技術對標英偉達 GPU 生態成熟方案,補齊了 TPU 長期缺失的高速互聯能力。
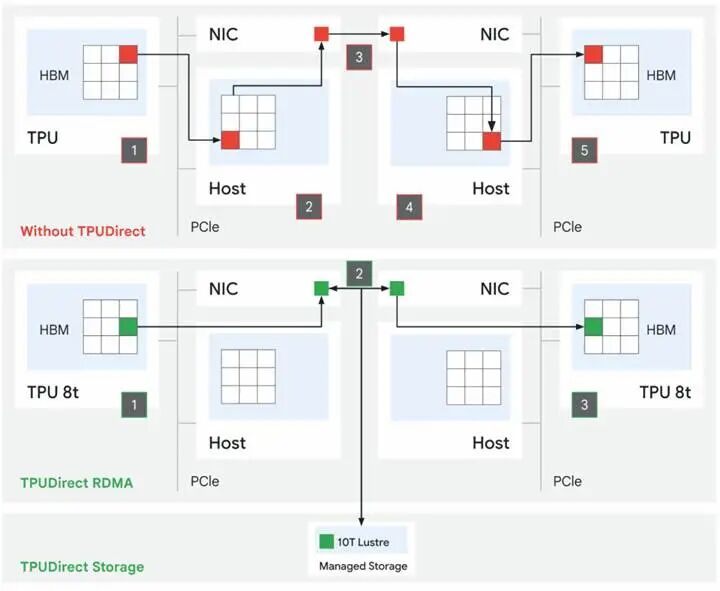
實測結果顯示,在谷歌托管級 Lustre 10T 存儲服務中,TPU 直連存儲技術可將存儲訪問性能提升 10 倍,徹底解決上一代 TPU 平臺存儲 IO 瓶頸。而TPU 內存 RDMA 互聯的具體性能提升幅度,谷歌暫未公開細節。

評論