一種基于FPGA的QC_LDPC碼的譯碼器設計

文獻中也給出了4環和6環的檢驗算法,同時可驗證按照此方法得到的校驗矩陣最小圍長為8。
本文引用地址:http://www.cqxgywz.com/article/246737.htm2 QC_LDPC碼的譯碼算法
置信傳播(Belief Propagation,BP)算法是LDPC的標準譯碼算法,在其基礎上又可改進得到最小和(Min-Sum)算法、歸一化最小和(Nor malization Min-Sum,NMS)算法等。此類算法皆通過校檢節點更新和變量節點更新兩步完成一次譯碼迭代,因此又稱為2項迭代置信傳播(Two Phase Message Passing,TPMP)算法。TPMP算法因為在一次迭代過程中,全部校檢節點更新完后,才對所有變量節點進行更新,所以在一次迭代過程中,所有信息只能進行一次更新,收斂速度較慢,譯碼延時較大。雖此后又提出了復用處理的方法,但未能從根本上提升算法的收斂性和譯碼性能。
2.1 QC_LDPC碼的分層譯碼策略
分層譯碼策略則改變了TPMP算法的譯碼方式,其將校檢矩陣按行或列劃分成若干分層。在一次迭代過程中,先并行更新第1分層中的所有校檢節點和相關的變量節點,然后逐層進行更新。因此在一次更新過程中,后更新的分層會利用已更新分層的輸出信息,變量節點在此過程中得到多次更新,大幅加快了譯碼的收斂速度,并提高了譯碼性能。但為確保變量節點信息在各分層之間能夠進行傳遞,校檢矩陣一個分層中的列權重必須<1。
2.2 分層迭代譯碼算法
由上述子矩陣移位法構造的是規則的QC_LDPC碼,因而采用分層譯碼時通常就是將校驗矩陣行重的一個子塊行作為一個分層,以碼長3 456,碼率為1/2的(3,6)正規QC_LDPC碼為例,基陣大小為108×216,填充矩陣塊為16×16,以每個子塊行作為一個分層即每個分層16行,共有108個子層。
設高斯白噪聲信道的噪聲方差為σ2,接收到的信號序列為y,校驗矩陣H的大小為M×N。迭代過程中信道固有信息Zn,校驗節點信息Lm,n,變量節點信息Zm,n,其中0≤m≤M-1,0≤n≤N-1。以BPSK調制為例,NMSA為基礎,將分層迭代譯碼算法的譯碼過程列述如下
(1)初始化
(2)迭代過程(第t次迭代的第k層)。
Step1分層更新。

Step2譯碼判決。若Zj<0,則
=1,否則
=0,更新譯碼結果
。 (3)譯碼結構校驗。完成一次迭代后,對更新的譯碼結果進行校驗。若滿足
xHT=0,或迭代次數達到系統設置的最大迭代次數,則停止譯碼,并輸出譯碼結果。否則,跳回步驟(2)進行新一次迭代。
3 正規QC_LDPC碼的譯碼器
3.1 譯碼器的結構
對碼長為3 456,碼率為1/2的(3,6)正規QC_LDPC碼,子矩陣大小為16×16,共有108個子塊行,216個子塊列,648個非零子矩陣。采用分層迭代譯碼算法實現譯碼器,譯碼過程中只保存Zn和Lm,n兩種中間數據,變量節點信息則通過式(2)計算得出,以減小數據存儲量。為便于硬件實現,選擇α=0.75作為修正因子,這樣只需簡單的帶符號位右移和加法運算便可完成數據修正。由于將每一個子塊行作為一個分層,因此譯碼器的并行度為108,即共需108個基本運算單元。對譯碼器中的數據進行6 bit量化,并對計算過程中產生的溢出數據采用截斷處理,這樣的量化處理使譯碼性能約有0.1 dB的損失,但節約了硬件資源。
圖1為分層譯碼器的整體硬件結構。
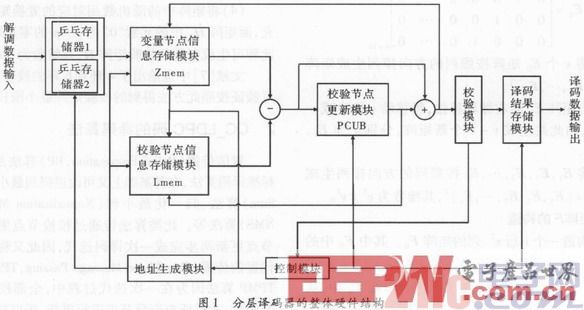
(1)數據輸入模塊。接收解調模塊輸出量化后的對數似然比數據,完成Zn的初始化。該模塊采用乒乓操作,即當其中一個存儲器接收數據的同時,譯碼器從另外一個存儲器中讀取數據進行譯碼,以此來提高譯碼器的吞吐量。
(2)數據存儲模塊。根據譯碼過程中所存儲數據的不同,存儲模塊可劃分為3塊:1)后驗概率存儲模塊Zmem,用于存儲Zn。單個Zn的長度為6位,每個子塊列對應的存儲空間為6×16=96位,對應子塊列數,共需216個此類模塊。2)校驗信息更新存儲模塊Lmem,用于存儲,單個的長度為6位,每一行有6個非零元素,所以每行對應的存儲空間為6×6=36位,而每一子塊行所對應的存儲空間為6×6×16=576位。對應子塊行數,共需108個此類存儲模塊。3)譯碼結果存儲模塊,用于存儲譯碼的結果。每一子塊列對應的譯碼數據長度為16位,對應子塊列數,共需216個此類存儲空間。同樣為了提高吞吐量,譯碼數據輸出模塊也采用乒乓操作,當一個存儲器進行譯碼結果更新時,另一個存儲器向外設輸出存儲器中的譯碼結果。
(3)校驗節點更新模塊(Parity—Check UpdateBlock,PCUB)。校驗節點模塊是譯碼器的核心處理單元,完成迭代的更新過程。共有108個PCUB模塊進行并行處理,一次更新108組數據。每一組相關的6個變量節點信息串行輸入PCUB中的FIFO寄存器,并逐次進行比較,尋找該組數據中的最小值與次最小值。當一組數據輸入完成后,最小值與次最小值得以確定,再從FIFO寄存器中依次讀出數據同最小值與次最小值比較,再更新數據。迭代譯碼過程主要被劃分成兩個階段,變量節點信息輸入FIFO階段和變量節點信息輸出FIFO階段。這樣的結構適合采用二級流水線,當一組已輸入的變量節點信息從FIFO中讀取時,將下一組變量節點信息輸入FIFO。通過二級流水線處理,提高了近一倍的數據吞吐率。

c++相關文章:c++教程











評論